 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation VAEs for 3D CT Reconstruction, Augmentation, and Generation
May 29, 2026Variational autoencoders (VAEs) compress high resolution CT volumes into compact latents while preserving clinically relevant structure. However, training CT-specific VAEs from scratch or heavily fine-tuning them incurs substantial computational and engineering cost, and often degrades under heterogeneous scanners, protocols, and diseases. This paper makes a progressive stride toward training-free medical VAEs by leveraging a critical observation: a single Foundation VAE, pretrained at scale on natural images and videos, can serve as a unified interface for CT Reconstruction, Augmentation, and Generation. With both encoder and decoder frozen, the Foundation VAE reconstructs CT volumes with preserved anatomy while suppressing acquisition noise; training segmentation models on these reconstructions improves surface accuracy by 3.9% NSD on average for pancreatic tumor and lung tumor. Within the same Foundation VAE latent space, a conditional latent diffusion model achieves 3.9% lower average FVD with 36.2% higher CT CLIP score, and improves multi-disease generation faithfulness across 18 types by 2.76% AUC. These results demonstrate Foundation VAEs as a practical interface for scalable CT representation reuse and faithful CT generation. Our code and demo are available at https://github.com/qic999/Foundation-VAE.
RadThinking: A Dataset for Longitudinal Clinical Reasoning in Radiology
May 11, 2026Cancer screening is a reasoning task. A radiologist observes findings, compares them to prior scans, integrates clinical context, and reaches a diagnostic conclusion confirmed by pathology. We present RadThinking, a Visual Question Answering (VQA) dataset that makes this reasoning explicit and trainable. RadThinking releases VQA pairs at three difficulty tiers. Foundation VQAs are atomic perception questions. Single-step reasoning VQAs apply one clinical rule. Compositional VQAs require multi-step chain-of-thought to reach a guideline category such as LI-RADS-5. For every compositional VQA, we release the chain of foundation VQAs that solves it. The chain follows the rules of the governing clinical reporting standard. The dataset spans 20,362 CT scans from 9,131 patients across 43 cancer groups, plus 2,077 verified healthy controls with >1-year follow-up. To our knowledge, RadThinking is the first cancer-screening VQA corpus that stratifies questions by reasoning depth and grounds compositions in clinical reporting standards. The foundation tier supplies atomic perception supervision. The compositional tier supplies chain-of-thought data and verifiable rewards for reinforcement-learning recipes such as DeepSeek-R1 and OpenAI o1. RadThinking enables systematic training and evaluation of whether AI systems can reason about cancer, not merely detect it.
DeepTumorVQA: A Hierarchical 3D CT Benchmark for Stage-Wise Evaluation of Medical VLMs and Tool-Augmented Agents
May 10, 2026Medical vision-language models (VLMs) and AI agents have made significant progress in learning to analyze and reason about clinical images. However, existing medical visual question answering (VQA) benchmarks collapse model capabilities into a single accuracy score, obscuring where and why models fail. We propose DeepTumorVQA, a hierarchical benchmark that follows the multi-stage evidence chain in tumor diagnosis and decomposes 3D CT reasoning into four stages: recognition, measurement, visual reasoning, and medical reasoning. Higher-level questions remain independently scorable, while their ground-truth evidence chains are defined over lower-level primitives. The benchmark contains 476K questions across 42 clinical subtypes on 9,262 3D CT volumes. In addition to a direct reasoning mode for VLMs, DeepTumorVQA provides tool-interaction environments for agent evaluation, where a model can call external tools, including segmentation models, measurement programs, and medical knowledge modules, before answering the question. Evaluating over 30 model configurations, we find that reliable quantitative measurement is the primary bottleneck, making later-stage visual and medical reasoning harder for VLMs, while tool augmentation substantially mitigates this issue. When tools are available, leveraging medical knowledge and tools to reason about medical images becomes a new challenge. We further show that ground-truth step-by-step tool-use traces from DeepTumorVQA can supervise agents and reduce tool-use and reasoning failures. This stage-wise progression from recognition to measurement to visual and medical reasoning provides a concrete roadmap for future medical VLM and AI agent studies. All data and code are released at https://github.com/Schuture/DeepTumorVQA.
CrossPan: A Comprehensive Benchmark for Cross-Sequence Pancreas MRI Segmentation and Generalization
Apr 20, 2026Automatic pancreas segmentation is fundamental to abdominal MRI analysis, yet deep learning models trained on one MRI sequence often fail catastrophically when applied to another-a challenge that has received little systematic investigation. We introduce CrossPan, a multi-institutional benchmark comprising 1,386 3D scans across three routinely acquired sequences (T1-weighted, T2-weighted, and Out-of-Phase) from eight centers. Our experiments reveal three key findings. First, cross-sequence domain shifts are far more severe than cross-center variability: models achieving Dice scores above 0.85 in-domain collapse to near-zero (<0.02) when transferred across sequences. Second, state-of-the-art domain generalization methods provide negligible benefit under these physics-driven contrast inversions, whereas foundation models like MedSAM2 maintain moderate zero-shot performance through contrast-invariant shape priors. Third, semi-supervised learning offers gains only under stable intensity distributions and becomes unstable on sequences with high intra-organ variability. These results establish cross-sequence generalization-not model architecture or center diversity-as the primary barrier to clinically deployable pancreas MRI segmentation. Dataset and code are available at https://crosspan.netlify.app/.
Distilling Photon-Counting CT into Routine Chest CT through Clinically Validated Degradation Modeling
Apr 08, 2026Photon-counting CT (PCCT) provides superior image quality with higher spatial resolution and lower noise compared to conventional energy-integrating CT (EICT), but its limited clinical availability restricts large-scale research and clinical deployment. To bridge this gap, we propose SUMI, a simulated degradation-to-enhancement method that learns to reverse realistic acquisition artifacts in low-quality EICT by leveraging high-quality PCCT as reference. Our central insight is to explicitly model realistic acquisition degradations, transforming PCCT into clinically plausible lower-quality counterparts and learning to invert this process. The simulated degradations were validated for clinical realism by board-certified radiologists, enabling faithful supervision without requiring paired acquisitions at scale. As outcomes of this technical contribution, we: (1) train a latent diffusion model on 1,046 PCCTs, using an autoencoder first pre-trained on both these PCCTs and 405,379 EICTs from 145 hospitals to extract general CT latent features that we release for reuse in other generative medical imaging tasks; (2) construct a large-scale dataset of over 17,316 publicly available EICTs enhanced to PCCT-like quality, with radiologist-validated voxel-wise annotations of airway trees, arteries, veins, lungs, and lobes; and (3) demonstrate substantial improvements: across external data, SUMI outperforms state-of-the-art image translation methods by 15% in SSIM and 20% in PSNR, improves radiologist-rated clinical utility in reader studies, and enhances downstream top-ranking lesion detection performance, increasing sensitivity by up to 15% and F1 score by up to 10%. Our results suggest that emerging imaging advances can be systematically distilled into routine EICT using limited high-quality scans as reference.
Project Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
Mar 29, 2026Foundation models have demonstrated remarkable success across diverse domains and tasks, primarily due to the thrive of large-scale, diverse, and high-quality datasets. However, in the field of medical imaging, the curation and assembling of such medical datasets are highly challenging due to the reliance on clinical expertise and strict ethical and privacy constraints, resulting in a scarcity of large-scale unified medical datasets and hindering the development of powerful medical foundation models. In this work, we present the largest survey to date of medical image datasets, covering over 1,000 open-access datasets with a systematic catalog of their modalities, tasks, anatomies, annotations, limitations, and potential for integration. Our analysis exposes a landscape that is modest in scale, fragmented across narrowly scoped tasks, and unevenly distributed across organs and modalities, which in turn limits the utility of existing medical image datasets for developing versatile and robust medical foundation models. To turn fragmentation into scale, we propose a metadata-driven fusion paradigm (MDFP) that integrates public datasets with shared modalities or tasks, thereby transforming multiple small data silos into larger, more coherent resources. Building on MDFP, we release an interactive discovery portal that enables end-to-end, automated medical image dataset integration, and compile all surveyed datasets into a unified, structured table that clearly summarizes their key characteristics and provides reference links, offering the community an accessible and comprehensive repository. By charting the current terrain and offering a principled path to dataset consolidation, our survey provides a practical roadmap for scaling medical imaging corpora, supporting faster data discovery, more principled dataset creation, and more capable medical foundation models.
Meissa: Multi-modal Medical Agentic Intelligence
Mar 09, 2026Multi-modal large language models (MM-LLMs) have shown strong performance in medical image understanding and clinical reasoning. Recent medical agent systems extend them with tool use and multi-agent collaboration, enabling complex decision-making. However, these systems rely almost entirely on frontier models (e.g., GPT), whose API-based deployment incurs high cost, high latency, and privacy risks that conflict with on-premise clinical requirements. We present Meissa, a lightweight 4B-parameter medical MM-LLM that brings agentic capability offline. Instead of imitating static answers, Meissa learns both when to engage external interaction (strategy selection) and how to execute multi-step interaction (strategy execution) by distilling structured trajectories from frontier models. Specifically, we propose: (1) Unified trajectory modeling: trajectories (reasoning and action traces) are represented within a single state-action-observation formalism, allowing one model to generalize across heterogeneous medical environments. (2) Three-tier stratified supervision: the model's own errors trigger progressive escalation from direct reasoning to tool-augmented and multi-agent interaction, explicitly learning difficulty-aware strategy selection. (3) Prospective-retrospective supervision: pairing exploratory forward traces with hindsight-rationalized execution traces enables stable learning of effective interaction policies. Trained on 40K curated trajectories, Meissa matches or exceeds proprietary frontier agents in 10 of 16 evaluation settings across 13 medical benchmarks spanning radiology, pathology, and clinical reasoning. Using over 25x fewer parameters than typical frontier models like Gemini-3, Meissa operates fully offline with 22x lower end-to-end latency compared to API-based deployment. Data, models, and environments are released at https://github.com/Schuture/Meissa.
Early and Prediagnostic Detection of Pancreatic Cancer from Computed Tomography
Jan 29, 2026Pancreatic ductal adenocarcinoma (PDAC), one of the deadliest solid malignancies, is often detected at a late and inoperable stage. Retrospective reviews of prediagnostic CT scans, when conducted by expert radiologists aware that the patient later developed PDAC, frequently reveal lesions that were previously overlooked. To help detecting these lesions earlier, we developed an automated system named ePAI (early Pancreatic cancer detection with Artificial Intelligence). It was trained on data from 1,598 patients from a single medical center. In the internal test involving 1,009 patients, ePAI achieved an area under the receiver operating characteristic curve (AUC) of 0.939-0.999, a sensitivity of 95.3%, and a specificity of 98.7% for detecting small PDAC less than 2 cm in diameter, precisely localizing PDAC as small as 2 mm. In an external test involving 7,158 patients across 6 centers, ePAI achieved an AUC of 0.918-0.945, a sensitivity of 91.5%, and a specificity of 88.0%, precisely localizing PDAC as small as 5 mm. Importantly, ePAI detected PDACs on prediagnostic CT scans obtained 3 to 36 months before clinical diagnosis that had originally been overlooked by radiologists. It successfully detected and localized PDACs in 75 of 159 patients, with a median lead time of 347 days before clinical diagnosis. Our multi-reader study showed that ePAI significantly outperformed 30 board-certified radiologists by 50.3% (P < 0.05) in sensitivity while maintaining a comparable specificity of 95.4% in detecting PDACs early and prediagnostic. These findings suggest its potential of ePAI as an assistive tool to improve early detection of pancreatic cancer.
Large-Scale Label Quality Assessment for Medical Segmentation via a Vision-Language Judge and Synthetic Data
Jan 20, 2026Large-scale medical segmentation datasets often combine manual and pseudo-labels of uneven quality, which can compromise training and evaluation. Low-quality labels may hamper performance and make the model training less robust. To address this issue, we propose SegAE (Segmentation Assessment Engine), a lightweight vision-language model (VLM) that automatically predicts label quality across 142 anatomical structures. Trained on over four million image-label pairs with quality scores, SegAE achieves a high correlation coefficient of 0.902 with ground-truth Dice similarity and evaluates a 3D mask in 0.06s. SegAE shows several practical benefits: (I) Our analysis reveals widespread low-quality labeling across public datasets; (II) SegAE improves data efficiency and training performance in active and semi-supervised learning, reducing dataset annotation cost by one-third and quality-checking time by 70% per label. This tool provides a simple and effective solution for quality control in large-scale medical segmentation datasets. The dataset, model weights, and codes are released at https://github.com/Schuture/SegAE.
Auditing Significance, Metric Choice, and Demographic Fairness in Medical AI Challenges
Dec 22, 2025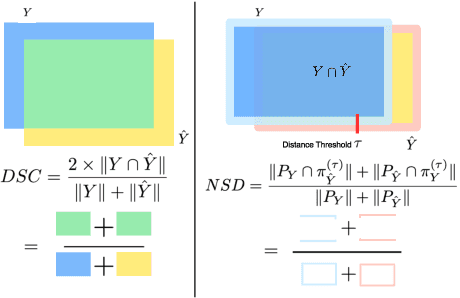
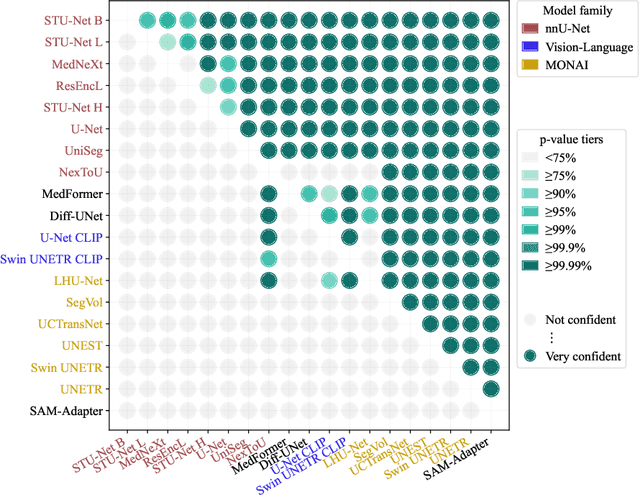
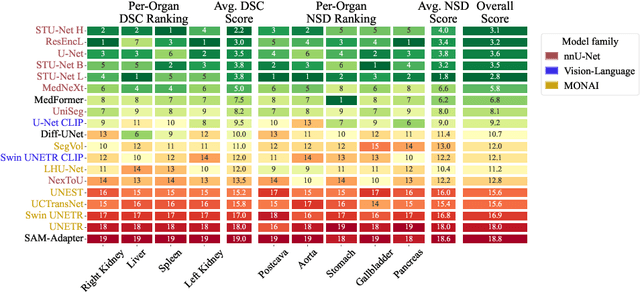
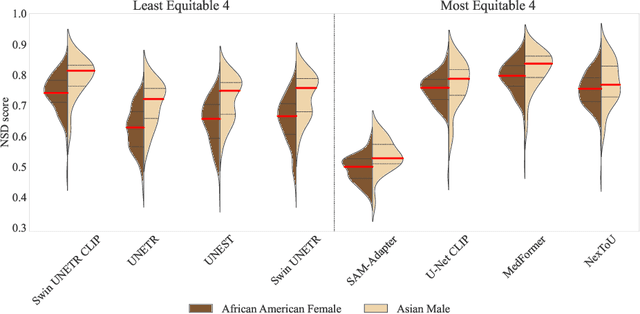
Open challenges have become the de facto standard for comparative ranking of medical AI methods. Despite their importance, medical AI leaderboards exhibit three persistent limitations: (1) score gaps are rarely tested for statistical significance, so rank stability is unknown; (2) single averaged metrics are applied to every organ, hiding clinically important boundary errors; (3) performance across intersecting demographics is seldom reported, masking fairness and equity gaps. We introduce RankInsight, an open-source toolkit that seeks to address these limitations. RankInsight (1) computes pair-wise significance maps that show the nnU-Net family outperforms Vision-Language and MONAI submissions with high statistical certainty; (2) recomputes leaderboards with organ-appropriate metrics, reversing the order of the top four models when Dice is replaced by NSD for tubular structures; and (3) audits intersectional fairness, revealing that more than half of the MONAI-based entries have the largest gender-race discrepancy on our proprietary Johns Hopkins Hospital dataset. The RankInsight toolkit is publicly released and can be directly applied to past, ongoing, and future challenges. It enables organizers and participants to publish rankings that are statistically sound, clinically meaningful, and demographically fair.